
向量搜索的局限探究
以 LLM 为基础的知识问答系统构建方法核心在于:
- 将用户问题和本地知识进行 Embedding,通过向量相似度 (Vector Similarity) 实现召回;
- 通过 LLM 对用户问题进行意图识别;并对原始答案加工整合。
在上一篇文章中进行了实践,发现存在以下问题:
- 用户意图识别精度低
- 搜索召回精度低
用户意图识别精度低
我们总是期望以较低的成本获得较好的结果。上文中提到搜索 Obsidian,这个意图就是不清晰的,是 Obsidian 的官网,还是插件,还是内容,还是分享,这些都是不明确的。以一个单词快速检索出内心想要的东西,甚至自己都没想明白只有一个关键字,传递给电脑大概率得到的结果也很敷衍。
Zero-Shot Information Extraction via Chatting with ChatGPT: https://arxiv.org/abs/2302.10205
Precise Zero-Shot Dense Retrieval without Relevance Labels 一文面向 zero-shot 场景下的稠密检索,使用基础模型在训练过程中已经掌握的相关语料,面向用户问题,生成虚构的文档。该文档的作用,不是输出最终结果,而是通过 LLM 对问题的理解能力,生成与之相关的内容。这相当于自动化生成相关性标签,避免外部输入。虚构文档生成后,再使用无监督检索器进行 Embedding;然后将生成的向量在本地知识库中进行相似性检索,寻找最终结果。
简单来说就是:
- 预设场景,提供背景内容,定制对应的语义槽
- 通过深度学习,统计学习,LLM 理解问题提取出所需要的内容
搜索召回精度低
试用向量搜索搜索 Obsidian,在返回结果中可以很明显的发现并不是包含 Obsidian 的结果都得到了返回,同时还会返回语雀、开源笔记等内容,这就是所谓的召回精度低:
- 返回结果不全
- 返回结果掺杂了部分无关的东西
- 搜索结果的关联几乎完全忽略
这个是由文本转换为向量这个步骤导致的,提高向量维度能解决返回结果不全的问题,但其泛化能力会得到削弱。减少向量维度泛化能力能得到提高,但失去了准确度。这几乎是一个无解的问题,因为我们既想要搜索 Obsidian 的全部结果,又想要与 Obsidian 近义的结果,比如黑曜石,obsidian,ob。1536 维的向量是 GPT 的 embedding 模型推荐的,应该是目前能调的最好的结果。
当然,也可以先进行全文搜索 Obsidain,ob,黑曜石 等关键字,和向量搜索得到的结果一起喂给 GPT,但 GPT 会存在同样的问题。它不会按部就班的返回所有结果,会选择性的对向量搜索得到的结果进行加工。
同样的,如果我在内容中写上:“Obsidian 是一款笔记软件”,“黑曜石诞生于 2020 年”,转化成向量就是两个完全无关的向量了。如果我搜索“Obsidian 在那哪一年开始开发的”,向量搜索大概率不会把上述两个结果同时返回。如果你不给清楚上下文直接送给 GPT,那么大概率还会碰到另一个问题——GPT 瞎编。
- 增加关键词,主题词检索:主题词由机构定义和发布的规范词,通常是专有名词或名词短语。这个过程可以使用反向词典。
- 对相同知识点建立多级索引:同一知识点通常涉及多个维度,建立多级索引可以让其在多维度查询下发挥作用。
- 结合知识图谱:知识图谱的三元组:实体、属性和关系。实体表示现实世界中的某个事物或对象,属性表示这个事物或对象的特征或属性,关系表示实体之间的关系。知识三元组可以帮助人们更好地理解和组织知识,并支持推理和问题解决。在问答系统中可以通过提示词引导 LLM 从用户的问题中提取知识三元组,然后在知识图数据库中进行查询。
上述过程是从无标注文本实现信息抽取(Information Extraction,IE),信息抽取有三类任务:
- 实体关系三元组抽取
- 命名实体识别
- 事件抽取
这是一个分词,词性标注,NER 识别,确定关系(依存关系,并列关系,修饰关系,从属关系,限定词等)的过程。
而这三类任务在知识问答的场景下,可简化为两个过程:
- 名词短语提取
- 谓语提取
而要做上述两个过程,有下列办法:
- LLM 提取:结果不准确、开销大。
- 传统 NLP 提取:业界已经有不少传统 NLP 工具可以使用,CoreNLP 和 HanLP 就是就是其中的佼佼者,对中文支持好,依赖少。首先根据正确的词性标注,构建出语法树,从语法的角度提取名词和短语。
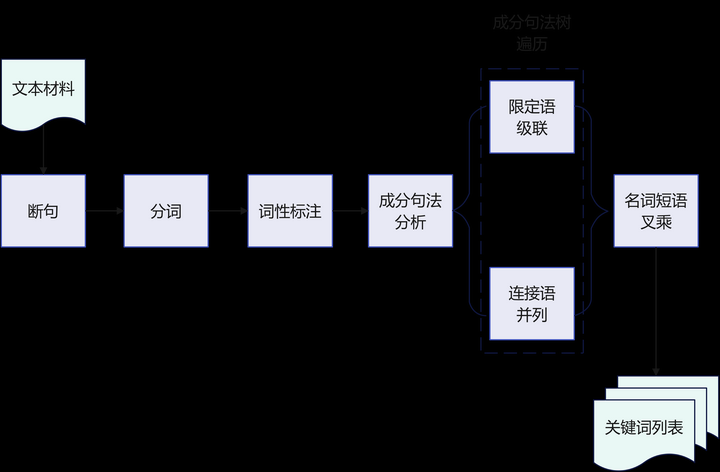
- 基于传统 NLP 的成分句法分析,提取名词短语;再通过短语间的依存关系,生成关键词列表
- 从完整语句的 Embedding,切换为关键词 Embedding:
- 知识库构建时。基于单知识点入库,入库时提取关键词列表进行 Embedding,用于检索。
- 查询时。对用户的问题提取关键词列表进行 Embedding 后,从本地知识库命中多条记录。
- 将单问句中的多知识点拆解后检索,将召回的多条记录交付给 LLM 整合。
该方法的优势在于:
- 相比传统 Embedding,大幅提升召回精准度。
- 支持单次交互,对多知识点进行聚合处理。而不必让用户,手动分别查询单个知识点,然后让 LLM 对会话历史中的单个知识点进行汇总。
- 使用传统 NLP 在专项问题处理上,相比 LLM 提供更好的精度和性能。
- 减少了对 LLM 的交互频次;提升了交付给 LLM 的有效信息密度;大大提升问答系统的交互速度。
我并没有使用 langchain 实际测试这样做的效果,可想而知这非常受限于文本处理的结果。对于信息提取得好的文本,搜索效果就会好,否则可能不尽如人意。关键词提取,依存句法分析,成分句法分析,构建知识图谱,创建向量搜索,处理问题,调用 LLM,这一系列操作成本颇高,在大量文本面前可能不是个人所能承受的。
总结
综上,向量搜索配合 LLM 想要达到稍微理想的程度,得花大功夫从两方面入手:
- 从输入入手,建立问题背景,进行意图识别
- 从搜索入手,增加关键字,建立多级索引和知识图谱
这些操作实际上已经和 LLM 没有太大关系了,此时的 LLM 起到汇总和润色的功能。谷歌早就在在搜索引擎上采取 rank,词性识别等操作,其搜索效果依然没有想象中好使。如果想要精确的找到想要的东西,传统搜索方式似乎是更好的选择。